What is Azure Machine Learning?
The power of data through machine learning (ML) has become essential for organizations looking to innovate and stay ahead. Microsoft Azure Machine Learning (Azure ML) stands out as a robust cloud-based platform designed to facilitate the entire lifecycle of machine learning projects. Whether you’re a data scientist, software engineer, or DevOps professional, Azure ML offers a comprehensive suite of tools to explore, build, deploy, and manage machine learning models seamlessly.
Azure Machine Learning Studio (ml.azure.com) serves as the user-friendly interface where users can access and manage Azure ML’s capabilities.
I highly recommend completing the exercise provided here.
You will use a dataset of historical bicycle rental data to train a model. The model predicts the number of bicycle rentals expected on a given day, based on seasonal and meteorological features.
Azure AI services
A suite of services covering Vision, Speech, Language, Decision, and Generative AI.
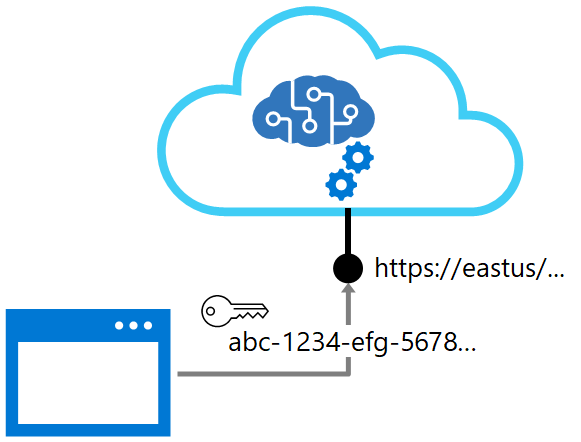
AI application resources in an Azure subscription:
- Standalone resources for specific services
- General Azure AI services resource for multiple services
Consumed by applications via:
- A REST endpoint (https://address)
- An authentication key or authorization token
Another exercise where you will explore the Content Safety Studio, create a resource and try out an Azure AI service – here.
What is Computer Vision?
Computer vision is a fundamental branch of artificial intelligence (AI) that focuses on developing technologies to enable AI-powered applications to “see” and interpret the world around them. By mimicking human vision, computer vision allows machines to analyze and understand visual information, making it a crucial component of modern AI solutions.
Azure Computer Vision
| Service | Description |
| Computer Vision | Image analysis – automated captioning and tagging Common object detection Face detection Smart cropping Optical character recognition Custom image classification Custom object detection |
| Face | Face detection and analysis Facial identification and recognition |
| Form Recognizer | Data extraction from forms, invoices, and other documents |
Images and image processing
Imagine opening a picture of your favorite pet on your computer. If it’s a grayscale image, each pixel in that picture is represented by a single value ranging from 0 (black) to 255 (white). The darker areas have lower values, while lighter areas approach 255. On the other hand, a color image isn’t just one grayscale image – it’s three. Each color channel – red, green, and blue (RGB)- has its own array of pixel values that together create the full-color picture you see.
To process these images effectively, we use filters. Filters are defined by small matrices of numbers called kernels. Think of it as sliding a window (the kernel) across the image pixel by pixel. At each position, the kernel values are multiplied by the corresponding pixel values in the image, and the results are summed up to produce a new pixel value in the filtered image. This process is repeated for every pixel, transforming the entire image according to the filter’s characteristics.
| An image is an array of pixel values | Filters are applied to change images |
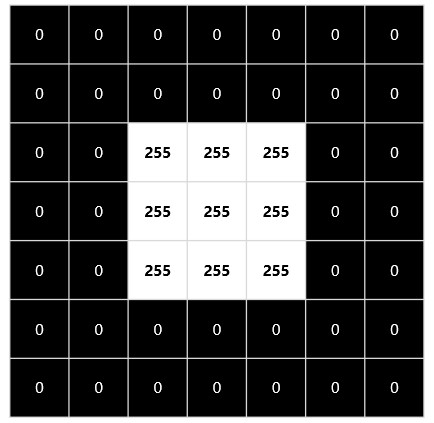 | 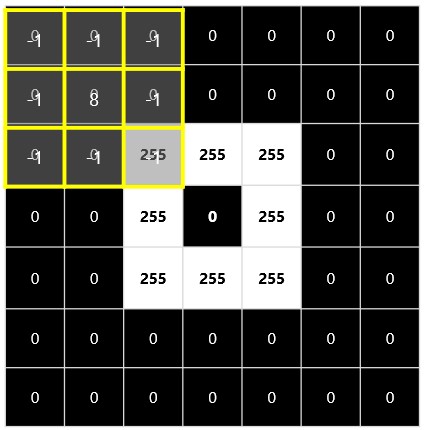 |
Convolutional Neural Networks
Convolutional neural networks (CNNs) stand out as a powerful model architecture. CNNs use filters to extract numeric feature maps from images, and then feed the feature values into a deep learning model to generate a label prediction.
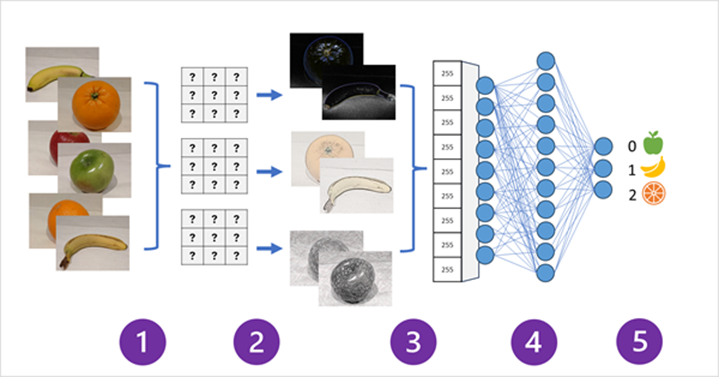
For instance, in a scenario where we want to classify images of fruits like apples, bananas, and oranges, a CNN learns to discern these fruits based on the unique features extracted by its filters. Throughout the training process, the CNN fine-tunes these filters by adjusting their weights to improve accuracy. As a result, the model becomes adept at identifying distinct characteristics that differentiate each type of fruit. By visualizing this process, we can better appreciate how CNNs transform raw image data into meaningful predictions, ultimately enabling sophisticated applications in image recognition and beyond.
Multi-modal models
The Microsoft Florence model, which is used for Image Analysis 4.0 capabilities in Azure AI Vision, is a multi-modal model. Trained with huge volumes of captioned images from the Internet, it includes both a language encoder and an image encoder. Florence is an example of a foundation model. In other words, a pre-trained general model on which you can build multiple adaptive models for specialist tasks.
For example, you can use Florence as a foundation model for adaptive models that perform:
- Image classification: Identifying to which category an image belongs.
- Object detection: Locating individual objects within an image.
- Captioning: Generating appropriate descriptions of images.
- Tagging: Compiling a list of relevant text tags for an image.
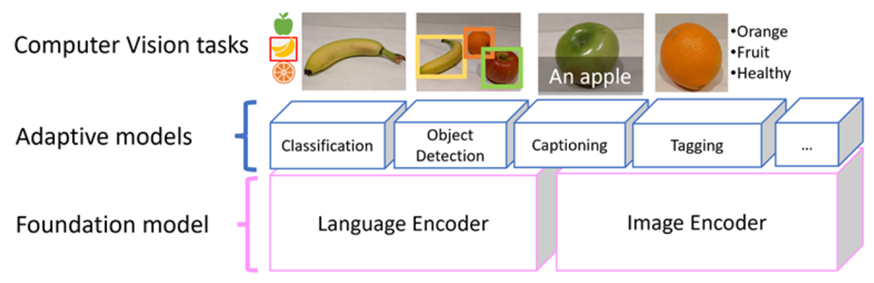
Computer Vision Capabilities in Azure
The Computer Vision service is a cognitive service in Microsoft Azure that provides pre-built computer
vision capabilities. The service can analyze images, and return detailed information about an image and
the objects it depicts
 |  |
| Image Analysis: Image tagging, captions, model customization, and more. Optical Character Recognition (OCR) Spatial analysis | Face detection Face recognition |
Image analysis 4.0 with the AI Vision Service
The Azure AI Vision Image Analysis service can extract a wide variety of visual features from your images. For example, it can determine whether an image contains adult content, find specific brands or objects, or find human faces.
You can use the Azure AI Vision Studio (portal.vision.cognitive.azure.com) to explore and test these capabilities.
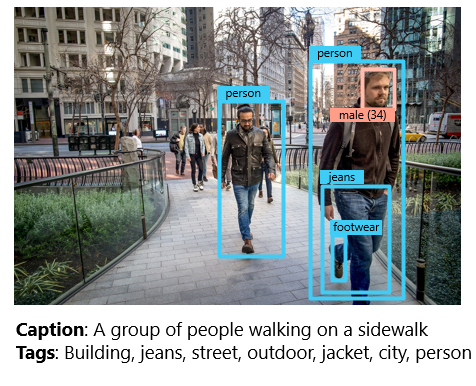
While the AI Vision service provides some basic face detection and analysis features, the Face service offers additional capabilities. All users can use the Face service to detect:
- Blur: how blurred the face is (which can be an indication of how likely the face is to be the main focus of the image)
- Exposure: aspects such as underexposed or over exposed and applies to the face in the image and not the overall image exposure
- Glasses: if the person is wearing glasses
- Head pose: the face’s orientation in a 3D space
- Noise: refers to visual noise in the image. If you have taken a photo with a high ISO setting for darker settings, you would notice this noise in the image. The image looks grainy or full of tiny dots that make the image less clear
- Occlusion: determines if there may be objects blocking the face in the image

Let’s take a look at the face detection capabilities of the Azure AI Face service using this exercise.
Reading text with Optical Character Recognition (OCR)
OCR capabilities are used to detect and extract text from images. The service provides the Read application programming interface (API) that software developers can use to extract both printed and handwritten text from images, from immediate reading of small amounts of text in images to asynchronous text extraction from large documents.

If you want to see Azure AI Vision’s optical character recognition capabilities in action, complete the following exercise.
To further explore and practice the concepts covered in this blog article, exercises are also accessible on Microsoft Learn. You can find them at https://microsoftlearning.github.io/mslearn-ai-fundamentals. Happy learning!