Bogdan Ionut Buruiana
Azure Solutions Architect Expert and a Microsoft Trainer
Originating from the land of Dracula, where the internet sinks its fiber-optic fangs into data packets, Bogdan crafts Azure solutions as sturdy as a Transylvanian fortress. Not only that, but as a Microsoft Trainer, he simplifies AI-900 to the point where it’s as effortless as enjoying a slice of pie—a sophisticated, high-tech pie, no less, with a flavor of the cloud and encased in a digital pastry shell.
AI Overview
Artificial intelligence, or AI, is all around us, even if we might not always realize it. Think about when you shop online and see recommendations for products you might like based on your past purchases. That’s AI at work, analyzing your preferences and predicting what you might want next. Or consider when you use your smartphone to take a picture, and it automatically recognizes faces or suggests edits—that’s AI too, enhancing our everyday experiences.
What is Artificial Intelligence?
At its core, AI is software that can predict outcomes and recognize patterns based on historical data. For instance, online streaming services use AI to analyze your watching habits and suggest new shows you might like. This is a practical example of AI in everyday life, making decisions based on the patterns it has learned from vast amounts of data.

AI is also adept at recognizing abnormal events and making decisions. Imagine a security system that monitors a building 24/7. It can differentiate between a stray animal in the premises and an actual intruder, and decide when to alert the authorities, ensuring safety while minimizing false alarms.
Interpreting visual input is another remarkable capability of AI. Autonomous vehicles for example – these vehicles use cameras and sensors to interpret traffic signals, road signs, and the presence of pedestrians or other cars, allowing them to navigate the roads with precision.
AI has made significant improvement in understanding language and engaging in conversations. Digital assistants on our phones and smart devices can understand spoken commands and respond in kind. They can set reminders, play music, or even order groceries with just a simple voice command.
Lastly, AI’s ability to extract information from sources to gain knowledge is exemplified by its use in medical diagnoses. AI systems can analyze medical images, such as X-rays or MRI scans, to help doctors detect diseases like cancer much earlier than before, which can be lifesaving.
Common AI workloads
| Machine Learning | ML is the art of teaching computers to learn from data and statistics, forming the foundation of AI. For example, Netflix uses machine learning algorithms to predict what movies or TV shows you’ll enjoy next, based on your viewing history. |
| Computer Vision | This AI capability enables machines to interpret the world visually, much like our own eyes. Take self-driving cars; they use computer vision to navigate roads, recognizing traffic lights, pedestrians, and other vehicles in real-time. |
| Natural Language Processing | Allows computers to understand and respond to human language. A great example is Siri or Alexa or Google, which can understand your questions and respond just like a human would. |
| Document Intelligence | It refers to AI’s ability to manage and process large amounts of data from documents. Consider how email filters work: they can sort through thousands of emails and categorize them into spam or important messages without any human intervention |
| Knowledge Mining | Is where AI extracts information from vast volumes of often unstructured data to create a searchable database. Legal firms, for instance, use knowledge mining to search is case files to find relevant information and references quickly |
| Generative AI | Gen AI is about creating original content. From AI writing simple news articles to composing music, it’s all about machines being creative. An exciting instance of this is AI art, where algorithms can create new artworks based on certain styles. |
Principles of responsible AI
Challenge or Risk | Example | |
| Fairness | Bias can affect results. | AI systems should treat all people fairly. For example, suppose you create a machine learning model to support a loan approval application for a bank. The model should make predictions of whether the loan should be approved without incorporating any bias based on gender, ethnicity, or other factors that might result in an unfair advantage or disadvantage to specific groups of applicants. |
| Reliability & safety | Errors may cause harm. | AI systems should perform reliably and safely. For example, consider an AI-based software system for an autonomous vehicle; or a machine learning model that diagnoses patient symptoms and recommends prescriptions. Unreliability in these kinds of system can result in substantial risk to human life. |
| Privacy & security | Private data could be exposed. | AI systems should be secure and respect privacy. The machine learning models on which AI systems are based rely on large volumes of data, which may contain personal details that must be kept private. Even after the models are trained and the system is in production, it uses new data to make predictions or take action that may be subject to privacy or security concerns. |
| Inclusiveness | Solutions may not work for everyone. | AI systems should empower everyone and engage people. AI should bring benefits to all parts of society, regardless of physical ability, gender, sexual orientation, ethnicity, or other factors. |
| Transparency | Users must trust a complex system. | AI systems should be understandable. Users should be made fully aware of the purpose of the system, how it works, and what limitations may be expected. |
| Accountability | Who’s liable for AI-driven decisions? | People should be accountable for AI systems. Designers and developers of AI-based solution should work within a framework of governance and organizational principles that ensure the solution meets ethical and legal standards that are clearly defined. |
What is machine learning?
Machine learning is about creating predictive models by finding relationships in data.
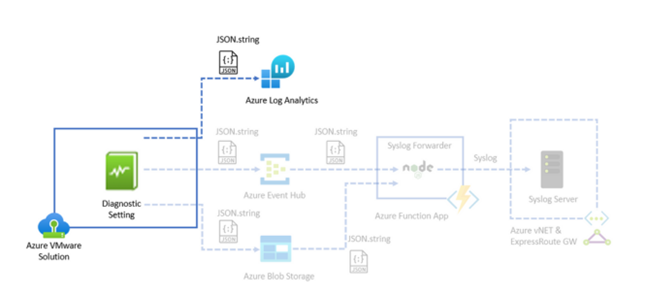
Imagine we have a vast amount of past observations — these are our training data. In these data, there are features, which are the observed attributes, and a label, which is what we aim to predict. Think of features as ingredients in a recipe, and the label as the final dish we want to create.
We apply an algorithm to this data. This algorithm is like a chef who tries different combinations of ingredients to perfect a recipe. The goal here is to find a relationship between the features (ingredients) and the label (the dish) and generalize this into a function that can predict the outcome.
The outcome of this process is a model — our perfected recipe, encapsulated in a function here. This model is now ready to make predictions.
Once our model is trained it is time to add new feature values — unseen data — into our model to make predictions.
Let’s think about a recommendation system for online shopping. The features might include your browsing history, the items you’ve clicked on, the time you’ve spent on certain products, and the label is the product you’re most likely to buy. The trained model then takes your new browsing data and predicts what you might want to purchase next — that’s inferencing.
Types of machine learning
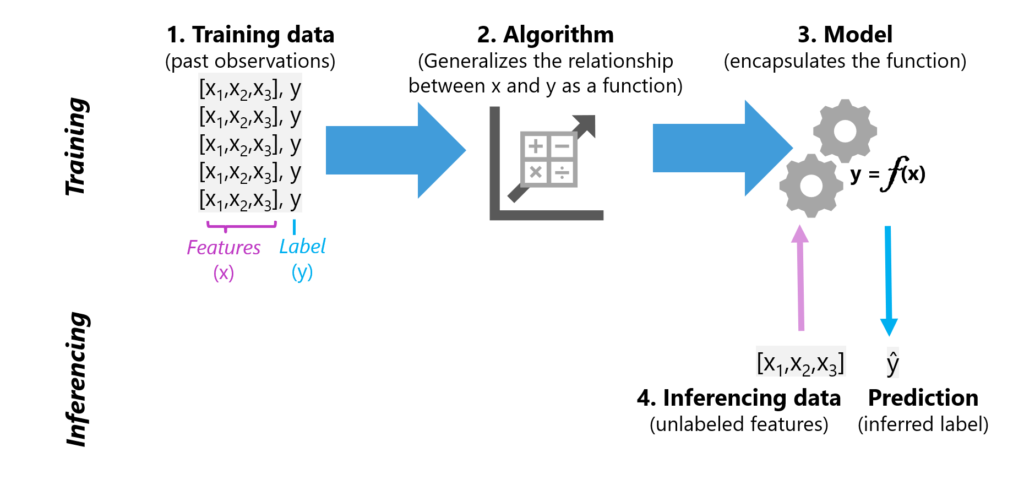
Machine learning is the science of teaching computers to learn from data, to make predictions or decisions, rather than following strictly static program instructions. There are primarily two types of machine learning: Supervised and Unsupervised.
In Supervised Machine Learning, we feed the computer with data that is well-labeled, which means we know the answer, and the algorithm learns to predict the output from the input data. It’s like when a student learning with the help of a teacher. The teacher provides examples for the student to memorize and later tests the student’s knowledge with similar, but new, problems.
Let’s consider a real-world application in healthcare: predicting diabetes. Here, the algorithm is trained with historical patient data, like age, weight, and blood glucose levels. This is like a medical student learning from past case studies to make a diagnosis.
Within Supervised Learning, we have two subcategories: Regression and Classification.
Regression predicts numerical values based on past data. For instance, predicting the number of ice creams that will be sold based on factors like the day’s temperature, rain, and wind speed.
On the other hand, Classification is used for predicting a category, like determining if an email is spam or not. We can further divide Classification into Binary Classification, where there are only two possible outcomes, and Multiclass Classification, where an object could belong to any one of multiple categories.
Unsupervised Machine Learning, on the contrary, works with unlabelled data. There’s no guide; the system tries to learn the patterns and the structure from the data by itself. Imagine a scenario where we want to group customers based on purchasing behavior without knowing any categories beforehand. Unsupervised learning algorithms will look for patterns in customer behavior to group similar customers together, a process known as Clustering.
To illustrate, consider a botanist wanting to categorize unknown plants. They would observe the features — like the size, petal count and so on — and group plants with similar characteristics. This is unsupervised learning at work, finding natural groupings without prior knowledge.
Model training and evaluation
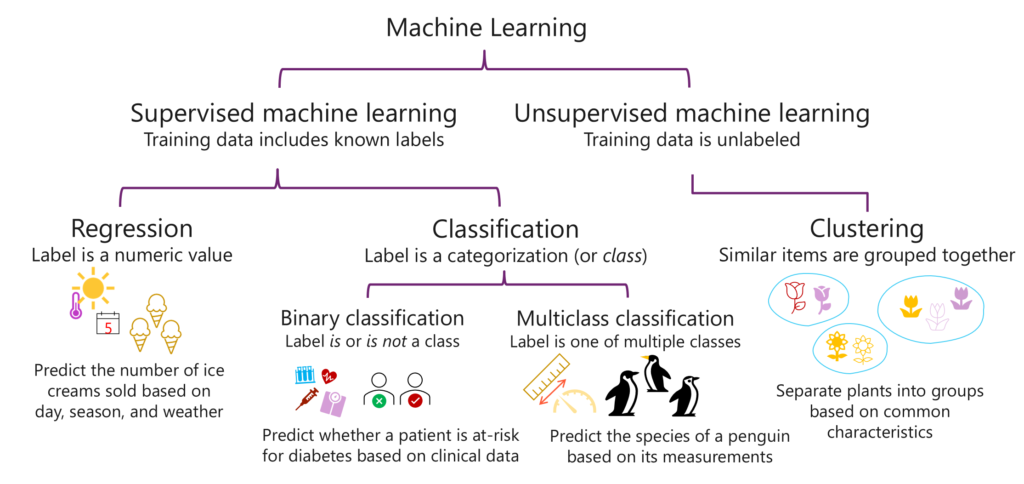
The first step in this process is to split our data into a training set and a validation set. The training set is like the practice field for our model, where it learns to understand the relationships within the data. For example, a retail company may use past sales data — that’s our training data — to predict future sales.
Once we have our training data, we apply an algorithm to fit this data to a model. This model will try to generalize the relationship between features, like the time of year and promotional activities, and the sales outcomes.
After our model is trained, it’s time to put it to the test. We do this by using the validation data, which the model hasn’t seen before, to generate predictions.
We then evaluate the model’s performance using metrics that compare the predicted labels to the actual labels. For our retail example, this means checking if the predicted sales numbers match up with the real sales data.
In supervised learning, this evaluation is straightforward as we have known labels to compare against. However, in unsupervised learning, where we don’t have labels — for instance, when clustering different customer behaviors — the evaluation focuses on how well the model can separate and identify distinct groups.
The iterative nature of this process cannot be overstated. We repeat these steps, fine-tuning the algorithms and parameters, striving for a model that accurately predicts real-world outcomes, despite some margin of error.
The ultimate goal in machine learning is to craft a model that mirrors reality as closely as possible. A real-world example would be again a streaming service that uses such a model to recommend movies. It trains on historical viewing data, validates predictions against current trends, and continuously improves its suggestions.
Deep learning
Deep learning is an advanced form of machine learning that tries to emulate the way the human brain learns. The key to deep learning is the creation of an artificial neural network that simulates electrochemical activity in biological neurons by using mathematical functions.
| Human neural network | Artificial neural network |
| Neurons fire in response to electrochemical stimuli When fired, the signal is passed to connected neurons | Each neuron is a function that operates on an input value (x) and a weight (w) The function is wrapped in an activation function that determines whether to pass the output on |

Artificial neural networks are made up of multiple layers of neurons – essentially defining a deeply nested function. This architecture is referred to as deep learning and the models produced by it are often referred to as deep neural networks (DNNs). You can use deep neural networks for many kinds of machine learning problem, including regression and classification, as well as more specialized models for natural language processing and computer vision.