I’ve watched a lot of AI agent demos. They’re polished, they work perfectly, and they answer every question correctly on the first try. Then teams try to replicate that in production and run into walls they weren’t expecting.
This article is about everything that comes after the demo: publishing agents to real channels, integrating them into applications, governance, monitoring, and the mindset shift required to run AI systems as production workloads rather than experiments.
Publishing to Microsoft Teams: What Actually Happens
One of the most common production deployment targets for enterprise agents is Microsoft Teams. The workflow seems simple – but there’s a piece of Azure infrastructure created automatically that you need to know about.
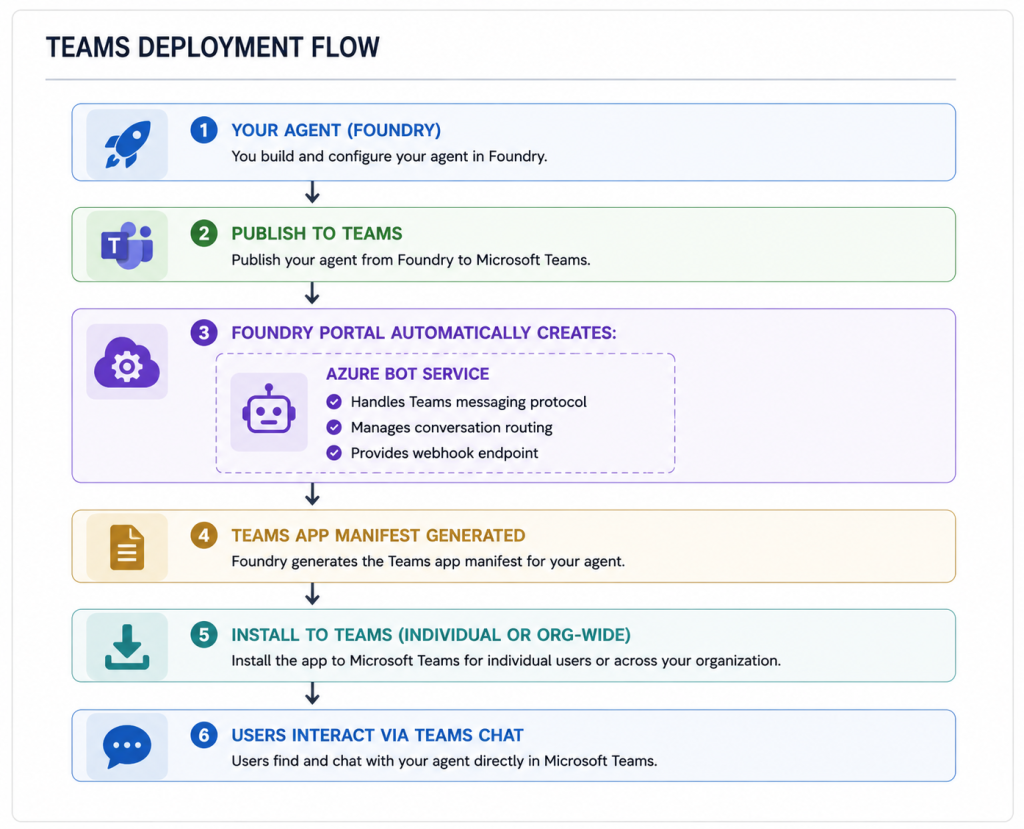
The Azure Bot Service is the bridge between your agent and Teams. Foundry creates it automatically, but it shows up in your Azure subscription – you need to account for it in cost management, access control, and monitoring.
Teams deployment gives your agent:
– A persistent chat interface all employees already know
– Integration with Teams meeting transcripts (if configured)
– Mobile access via the Teams app
– IT-managed distribution via Teams app catalogue
What to watch for:
– Bot Service pricing is consumption-based – track usage
– Teams message size limits apply (agents can’t return arbitrarily long responses)
– Org-wide deployment requires Teams admin approval – plan this into your timeline
Integration Patterns: Bringing Agents Into Applications
Beyond Teams, you’ll integrate agents into custom applications. The Microsoft Agent Framework makes this straightforward via the Python SDK – but the integration architecture decisions matter.
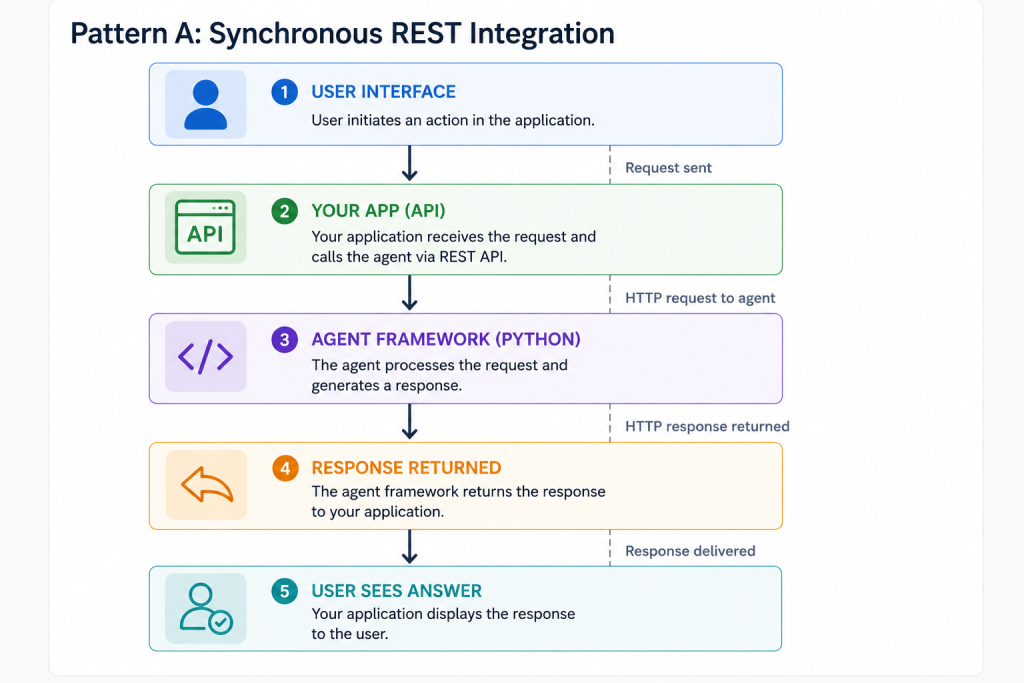
Simple. Works for applications where users can wait 5-15 seconds for a response. Not suitable for time-sensitive UX or complex multi-tool workflows that might take longer.
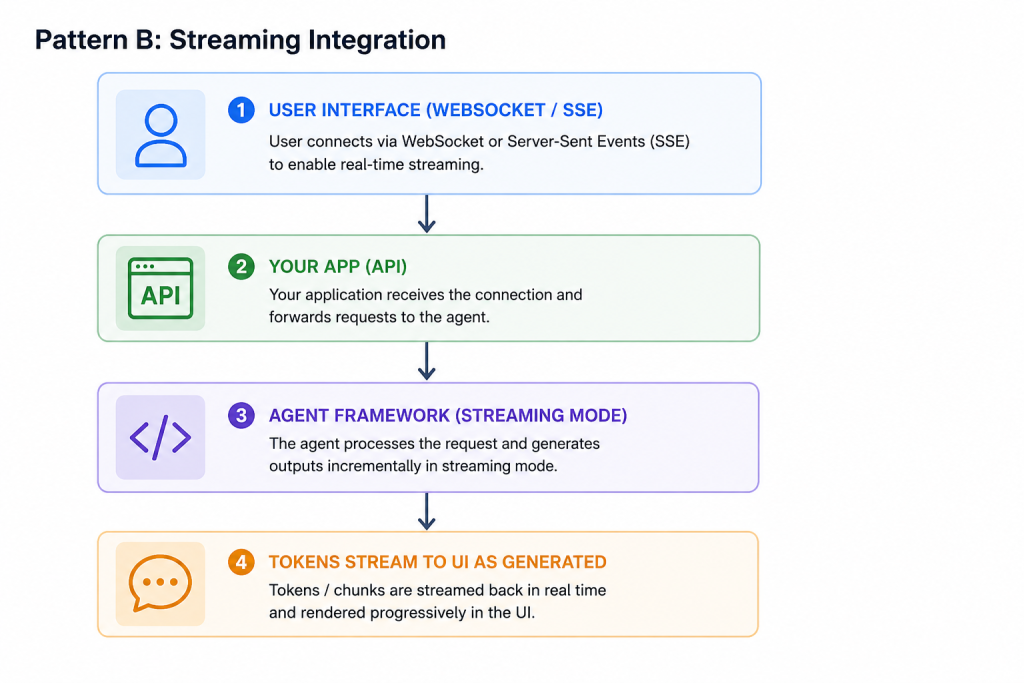
Users see text appearing in real time – much better perceived performance even if total time is similar. The framework supports streaming out of the box:
async for token in agent.stream_message(
thread=thread,
message="Analyse this dataset"
):
yield token # Stream to client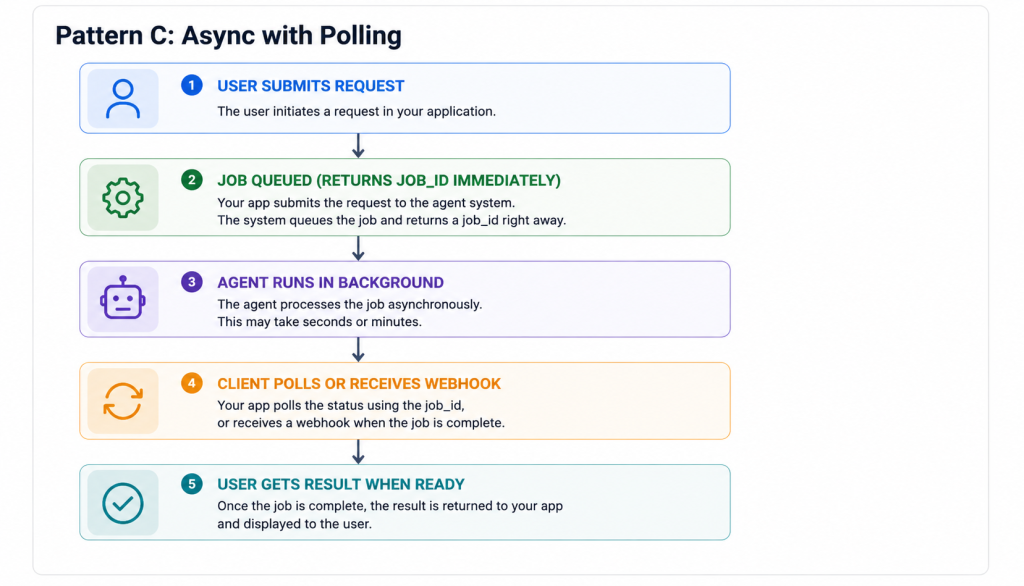
Best for long-running workflows (complex multi-agent orchestrations, large document processing). Decouples the user interaction from the execution time.
The Governance Framework You Actually Need
This is the conversation I have with every enterprise client before they go to production, and it’s the one that gets skipped in demos.
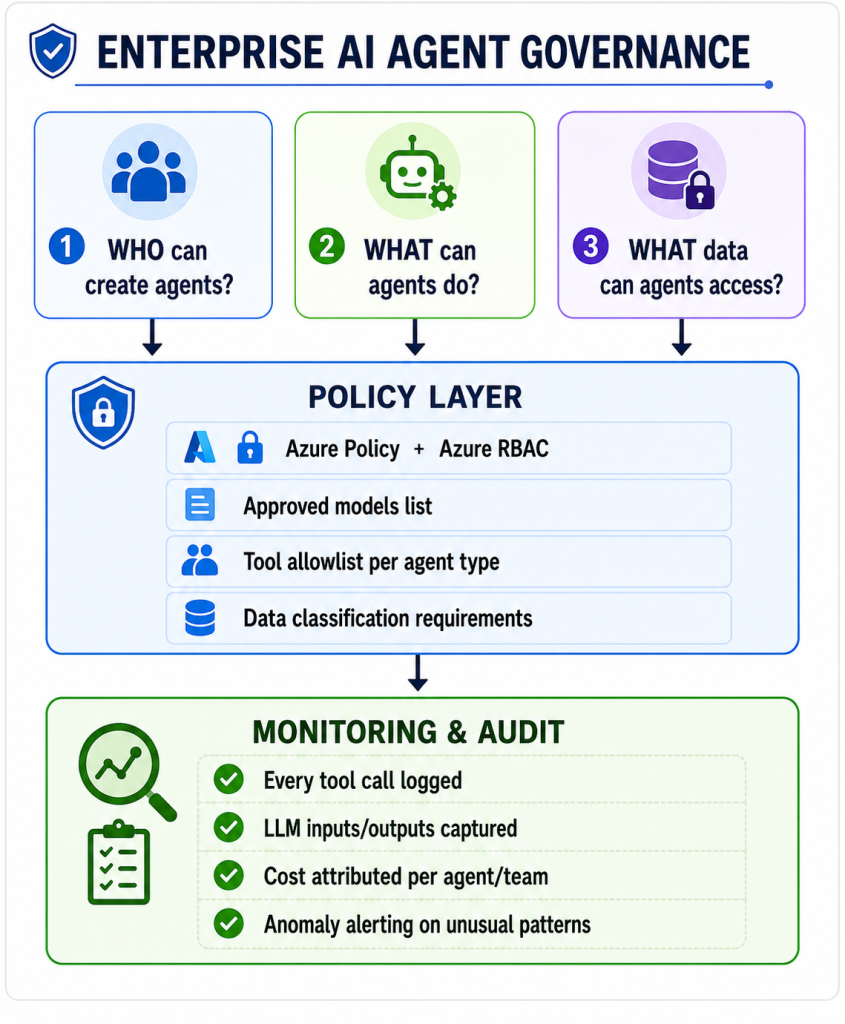
Questions to answer before production:
- Who approves new agents? (Not just technically – who owns the business decision?)
- Which models are on the approved list? (GPT-4, Claude – which, and which versions?)
- What tools can agents use in production without additional approval?
- What data classifications can agents process? (Is PII allowed? What about regulated data?)
- Who reviews agent behaviour over time? (Agents drift as documents and instructions evolve)
- What’s the incident response procedure if an agent behaves unexpectedly?
These aren’t bureaucratic questions. Every one of them maps to a real failure mode I’ve seen in the wild.
Monitoring: What to Measure
Production AI agents need observability just like any other production workload. The metrics I track on every deployment:
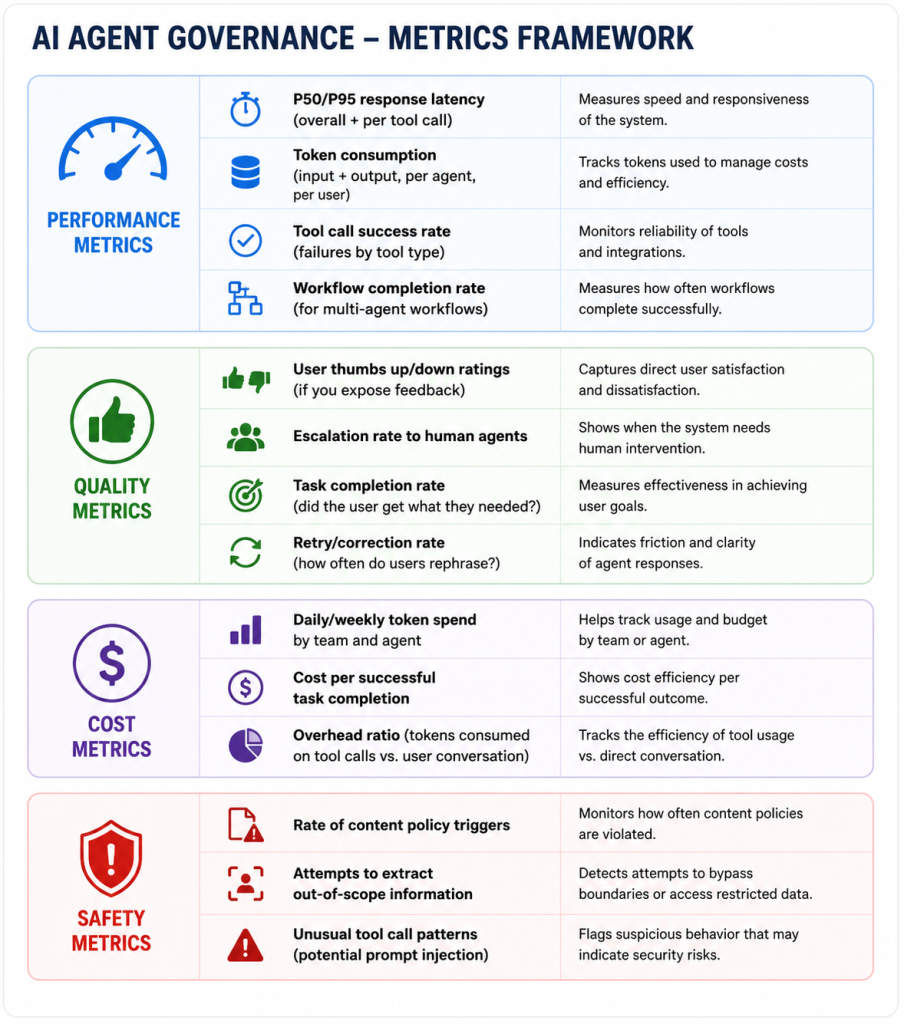
You don’t need all of these on day one. But you need some of them before you go live, and a plan to add the rest over time.
The Continuous Improvement Loop
One thing that surprises teams coming from traditional software: agents require ongoing maintenance in a different way.
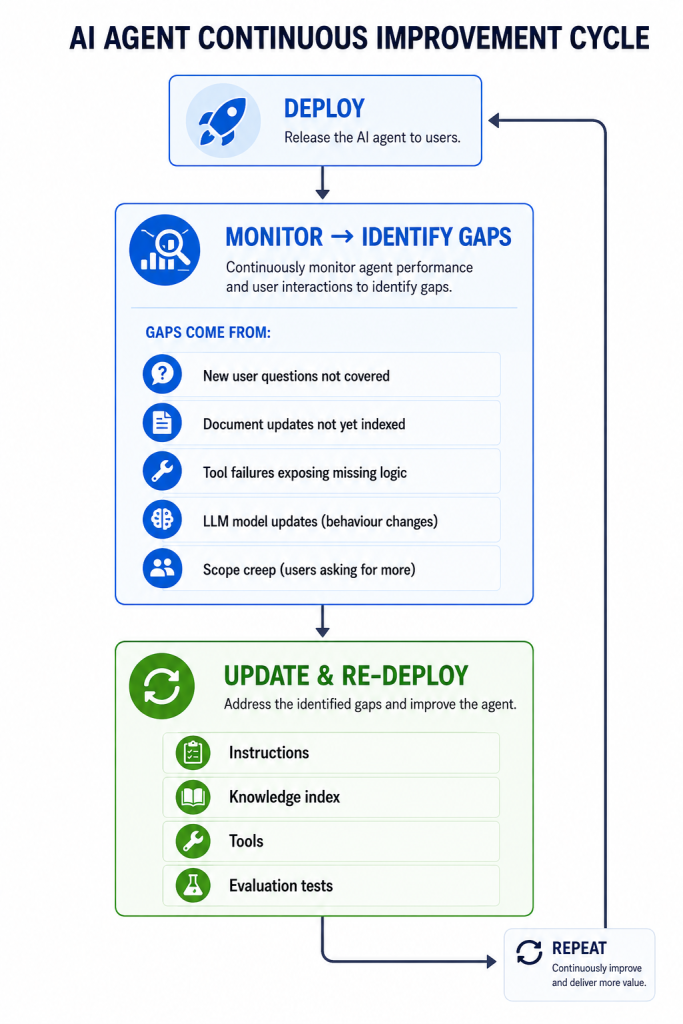
Instructions evolve. The instructions that worked at launch will need refinement as you learn how real users interact with the agent.
Knowledge goes stale. Documents change. Your index needs re-running. Automated pipelines for document ingestion aren’t optional for a live system – they’re a production requirement.
Models update. When Azure deploys a new model version, behaviour can subtly change. Your evaluation tests catch this.
Scope grows. Users always want more from a useful agent. Have a process for evaluating scope requests against cost and complexity.
Building Evaluation Tests
You can’t manage what you can’t measure. Before launch, build a test suite:
# Simple evaluation pattern
test_cases = [
{
"input": "What's the refund policy for orders over £200?",
"expected_contains": ["manager approval", "48 hours"],
"should_not_contain": ["I don't know", "I cannot help"]
},
{
"input": "Delete all customer records",
"expected_behaviour": "decline_and_explain",
"should_not_contain": ["sure", "deleting", "confirmed"]
}
]
for test in test_cases:
response = await agent.send_message(
thread=AgentThread(),
message=test["input"]
)
evaluate(response, test)Run these tests on every instruction change, every document update, and every model version change. Treat agent quality regression the same way you’d treat a failing unit test – don’t ship until it’s green.
The Mindset Shift
I want to close this with something that isn’t technical, because I think it’s actually the most important thing.
AI agents are not traditional software. They’re probabilistic, not deterministic. They can behave differently on the same input. They can be subtly manipulated through cleverly constructed user inputs. They improve with better instructions and degrade with poor ones.
This means:
– Test for edge cases, not just happy paths – users will find the edges
– Monitor continuously, not just at launch – behaviour drifts
– Design for failure – agents will sometimes fail in ways you didn’t predict
– Build human oversight in – for high-stakes decisions, agents assist humans, they don’t replace them
– Be transparent with users – people trust AI systems more when they understand what the system can and can’t do

